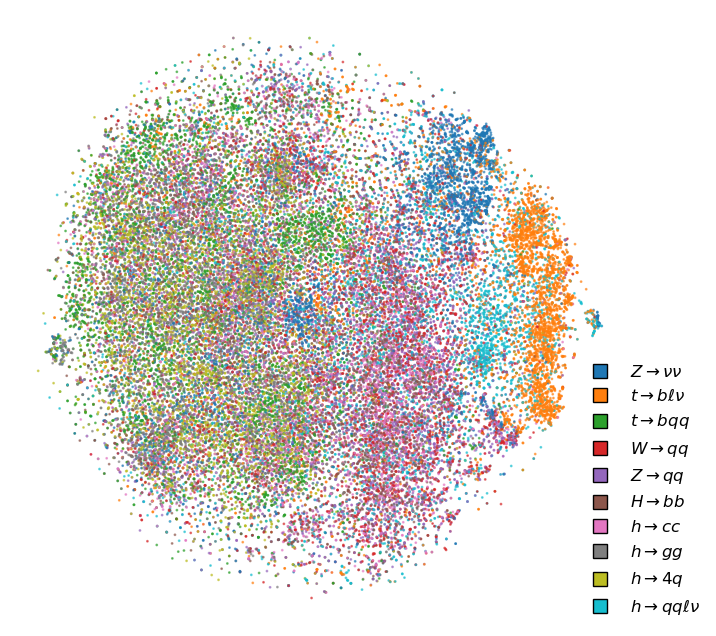
Experiments
Few-Shot Learning Evaluations
The model was evaluated on the JetClass dataset, where it consistently outperformed models trained from scratch, particularly in low-label regimes:
- Two regimes, frozen (pretrained backbone not updated) and fine-tuned were evaluated
- Evaluated at label fractions: 0.05%, 0.5%, 2%, 10%, and 100%
- Compared pre-trained HEP-JEPA model with model trained from scratch
Downstream Task Evaluations
The model was tested on two critical tasks:
- Top tagging using the Top Tagging Reference dataset
- Quark-gluon jet differentiation using the quark-gluon tagging dataset
Ablation Studies
The study explored various design choices, including:
- Masking strategies (random vs. contiguous token selection)
- Number of target tokens to predict
- Physics bias in the attention mechanism
- Integration of register tokens
- Impact of physics-inspired data augmentations